On-device AI for every platform.
Run open-source LLMs on your browser, phone, and desktop — no cloud required. Your data never leaves your device. Free, private, and fast.
Runs everywhere your users are.
The same on-device AI experience — adapted to each platform's strengths. WebGPU for browsers, Metal for iOS, Rust for desktops.
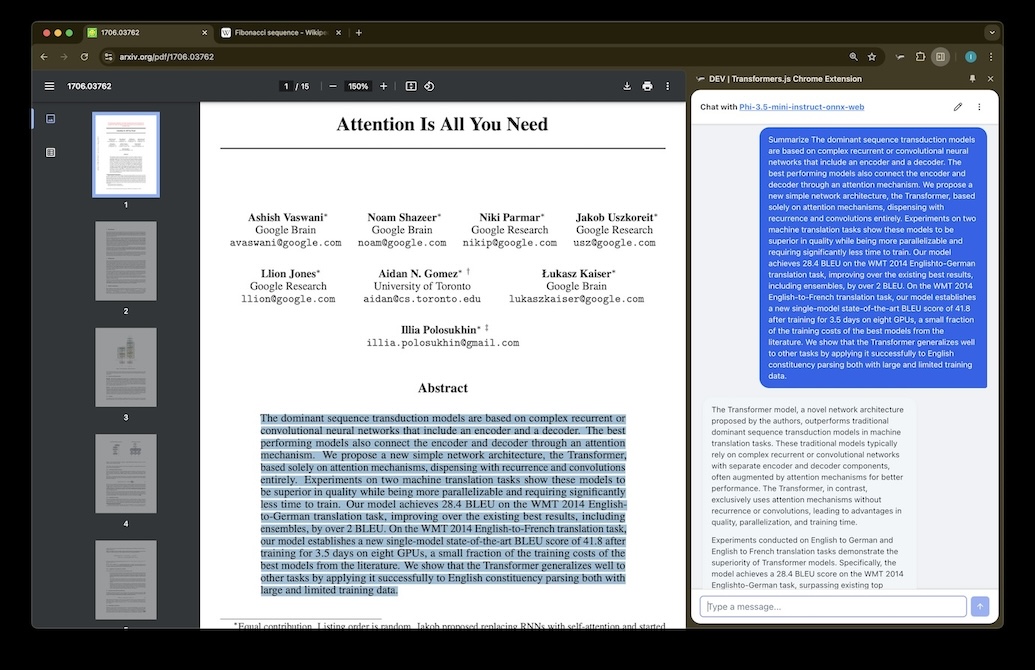
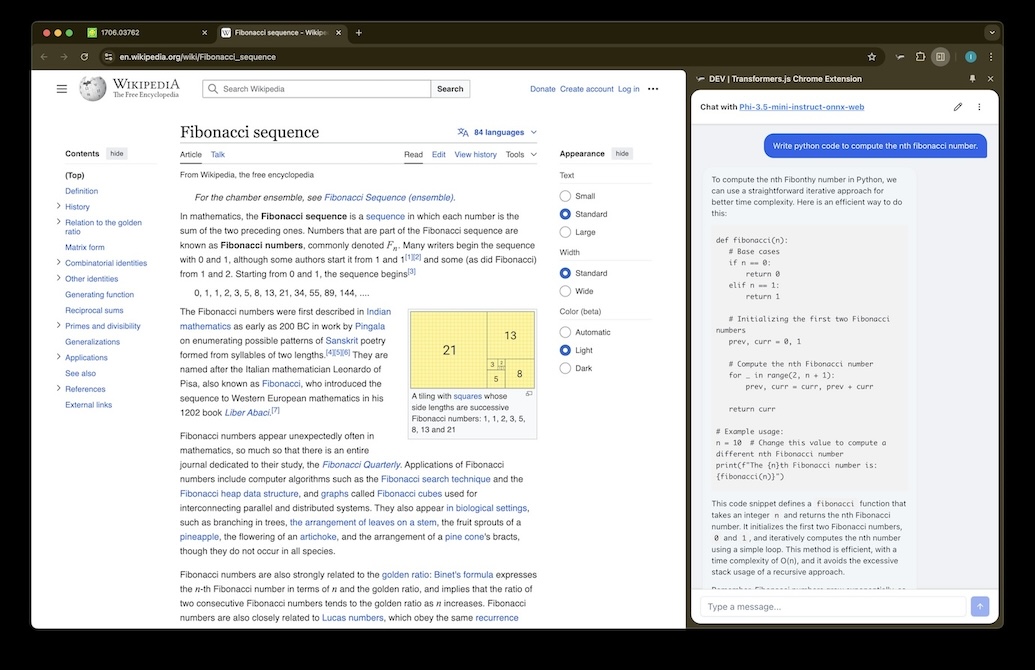
Browser Extension
AI sidebar for Chrome, Firefox & Safari. Powered by Transformers.js and WebGPU — runs directly in the service worker.
Plasmo · Transformers.js · ONNX · WebGPU
Chrome Web Store →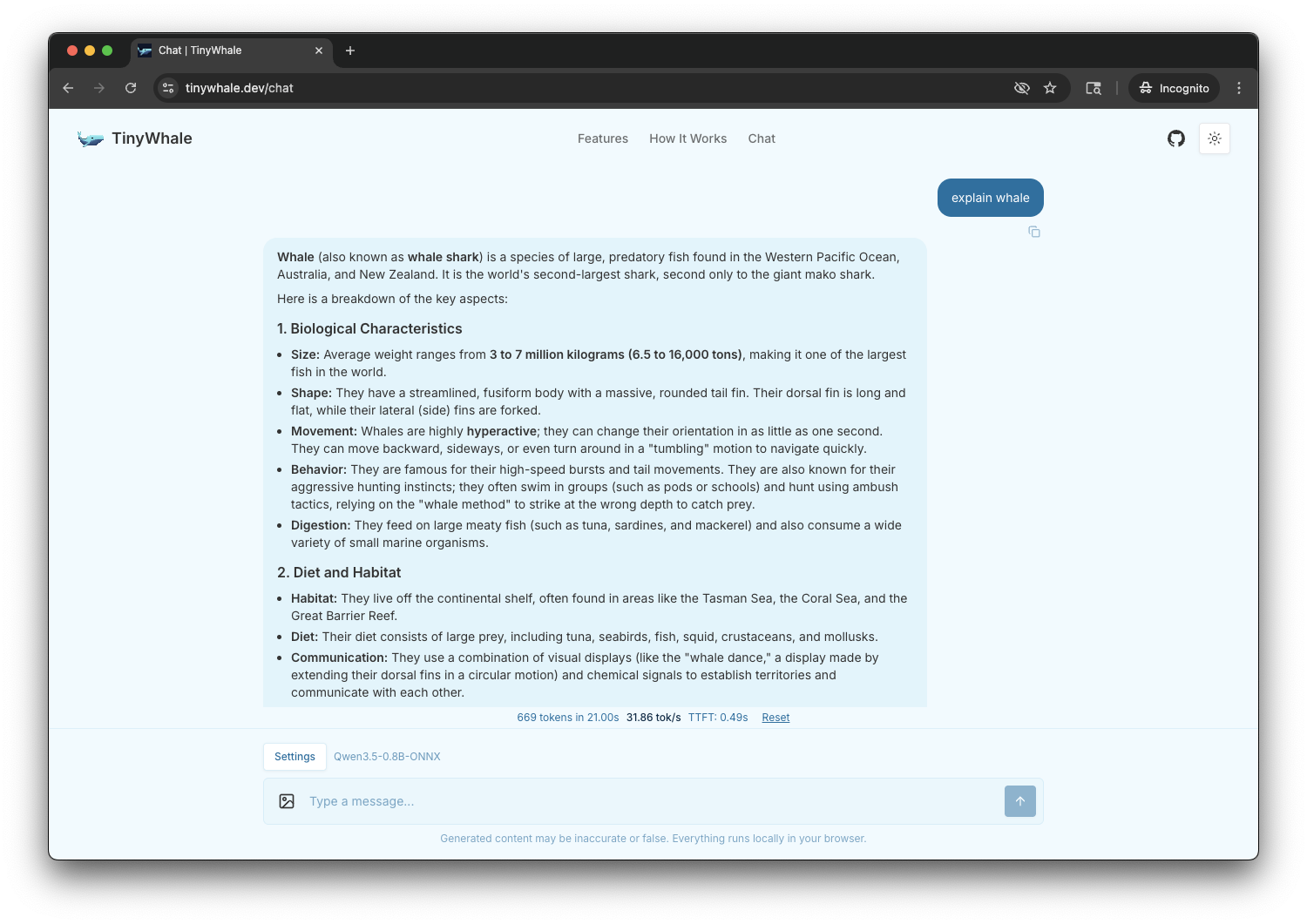
Web App
Chat with LLMs right in your browser tab. Web Worker keeps the UI smooth while the model runs on WebGPU.
Next.js · Transformers.js · ONNX · WebGPU
Try Demo →
Mobile
On-device LLM on iOS and Android. Native GPU acceleration via Metal and OpenCL through llama.cpp bindings.
Expo · llama.rn · GGUF · Metal
View on GitHub →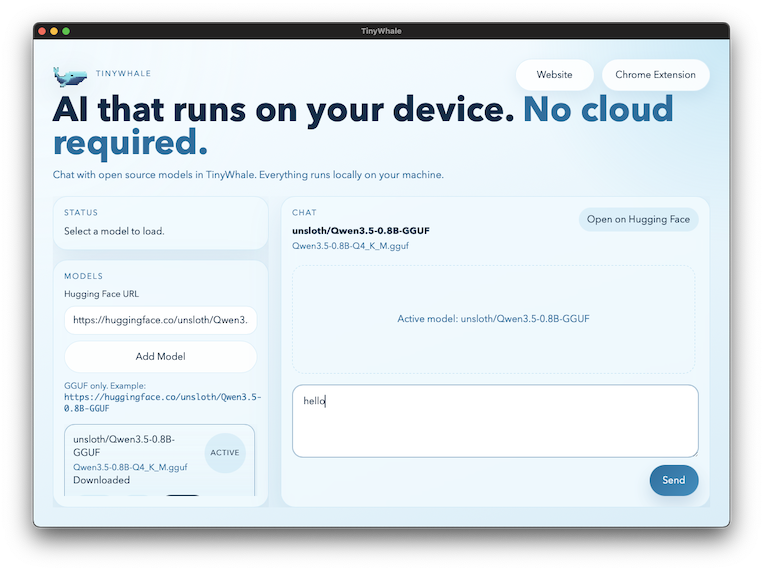
Desktop
Lightweight native app with Rust backend. Loads GGUF models from Hugging Face and runs inference via llama.cpp.
Tauri · Rust · llama.cpp · GGUF
View on GitHub →Your data never leaves your device.
All AI inference runs locally — in the browser via WebGPU, on your phone via Metal, or on your desktop via llama.cpp. No servers, no API calls, no telemetry.
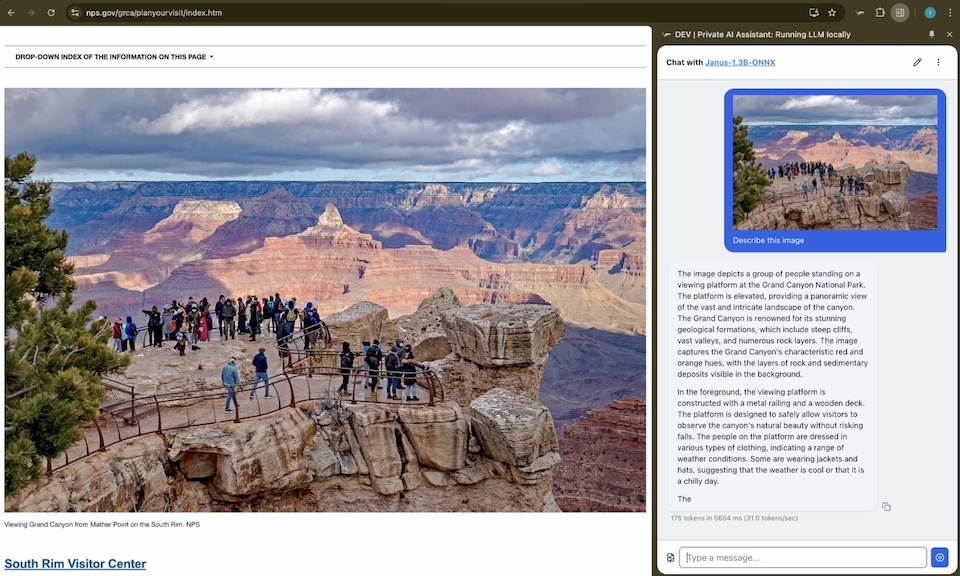
Understand images and text together.
Multimodal models process images and text locally on your device. Upload a photo and ask questions — no cloud needed.
Tune the model to your needs.
Adjust temperature, top-p, top-k, repetition penalty, and more. A local AI playground with fine-grained control over generation behavior.
Ready to dive in?
No sign-up required. No data collected. Pick your platform, load a model, and start chatting.